https://school.programmers.co.kr/learn/courses/30/lessons/12978
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr




풀이1 : 다익스트라 - 순차 탐색, 인접 배열
최단 경로 알고리즘을 사용하여 1번 마을부터 각 마을까지의 최단 시간(경로)를 구해야 한다.
최단 경로 알고리즘이란 주어진 그래프에서 한 정점(노드)에서 다른 정점까지의 최단 경로를 구하는 알고리즘이다.
대표적인 최단 경로 알고리즘은 3가지가 있다.
- 다익스트라 알고리즘 (default, 가중치가 모두 양수 = 음수X)
- 벨만 포드 알고리즘 (distance 값이 0이하가 존재할 때)
- 플로이드 알고리즘 (모든 시작점에 대해, 소스 코드 간단)
💡 다익스트라(dijkstra) 알고리즘은 그래프에서 한 정점(노드)에서 다른 정점까지의 최단 경로를 구하는 과정에서 도착 정점 뿐만 아니라 모든 다른 정점까지 최단 경로로 방문하며 각 정점까지의 최단 경로를 모두 찾게 된다. 매번 최단 경로의 정점을 선택해 탐색을 반복하는 것이다.
다익스트라 알고리즘 구현 방식은 2가지가 있다.
- 순차 탐색, 인접 배열 → O(V^2)
- 우선순위 큐, 인접 리스트 → O(ElogE), 또는 O(ElogV)
다익스트라 알고리즘을 구현하는 방법에는 '방문하지 않은 노드'를 다루는 방식에서 '순차 탐색'을 할 것이나 '우선순위 큐'를 쓸 것이냐로 나뉜다.
아래 풀이는 순차 탐색, 인접 배열을 사용한 1번째 풀이다.
1번째 풀이는 '방문하지 않은 노드 중 거리값이 가장 작은 노드'를 선택할 때 그 노드를 찾는 방식이 순차 탐색이 된다. 즉, 거리 테이블의 앞에서부터 찾아내야 하므로 노드의 개수만큼 순차 탐색을 수행해야 한다. 따라서 노드 개수가 N이라고 할 때 각 노드마다 최소 거리값을 갖는 노드를 선택해야 하는 순차 탐색이 수행되므로 의 시간이 걸린다.
아래 코드에서 dis[]는 각 노드까지의 최소 거리를 저장하고, visited[]는 방문 여부를, graph[][]은 한 노드에서 다른 노드로의 거리를 저장하고 있다.
로직
1. static 변수로 n, graph, visited, dis를 선언한다. n은 마을(정점)의 개수, graph는 인접 배열, visited는 그래프 정점 방문 여부, dis는 1번 정점에서 i번 정점까지의 최단 경로를 저장한다.
2. n, graph, visited, dis를 초기화하고 크기를 할당한다. 1번부터 시작하기 때문에 배열의 크기를 n+1만큼 할당한다.
3. graph 배열을 Integer.MAX_VALUE로 초기화한다.
4. road에 저장한 각 마을의 도로 정보를 사용해 graph 값을 채운다. 이 때 무방향 그래프이므로 graph[a][b] = graph[b][a] = c로 양방향 모두 저장한다. 이 때, 두 마을 a, b를 연결하는 도로는 여러 개가 있을 수 있으므로 작은 값을 저장한다.
5. 다익스트라 알고리즘을 수행하는 dijkstra(1)을 호출한다.
6. 1번 마을은 무조건 배달가능하므로 answer를 1로 초기화한다.
7. dis 배열을 for문으로 탐색하며 dis[i] <= K라면 answer에 1을 더한다.
8. answer를 리턴한다.
static void dijkstra(int start)
다익스트라 알고리즘을 사용하여 start 정점에서 모든 다른 정점까지의 최단 경로를 dis 배열에 저장한다.
static void dijkstra(int start) {
for (int i = 1; i <= n; i++)
dis[i] = graph[start][i];
dis[start] = 0;
visited[start] = true;
for (int i = 0; i < n - 1; i++) {
int cur = findSmallestNode();
visited[cur] = true;
for (int j = 1; j <= n; j++) {
if (!visited[j] && graph[cur][j] != Integer.MAX_VALUE) {
if (dis[j] > dis[cur] + graph[cur][j])
dis[j] = dis[cur] + graph[cur][j];
}
}
}
}- start 정점과 바로 연결되어있는 정점의 dis 값을 초기화한다.
- 방문하지 않은 노드 중 거리값이 가장 작은 노드를 선택하고, 선택한 노드와 연결된 정점들의 dis 값을 업데이트하며, 이 과정을 n - 1번 반복한다.
static int findSmallestNode()
방문하지 않은 노드 중 거리값이 가장 작은 노드의 번호를 반환한다.
static int findSmallestNode() {
int min = Integer.MAX_VALUE;
int v = 0;
for (int i = 1; i <= n; i++) {
if (!visited[i]) {
if (min > dis[i]) {
min = dis[i];
v = i;
}
}
}
return v;
}
코드
import java.util.*;
class Solution {
static int n;
static int[][] graph;
static boolean[] visited;
static int[] dis;
public int solution(int N, int[][] road, int K) {
n = N;
graph = new int[n+1][n+1];
visited = new boolean[n+1];
dis = new int[n+1];
for (int[] arr : graph) {
Arrays.fill(arr, Integer.MAX_VALUE);
}
for (int[] arr : road) {
int a = arr[0];
int b = arr[1];
int c = arr[2];
if (graph[a][b] > c) {
graph[a][b] = c;
graph[b][a] = c;
}
}
dijkstra(1);
int answer = 1;
for (int i = 2; i <= N; i++) {
if (dis[i] <= K)
answer++;
}
return answer;
}
static void dijkstra(int start) {
for (int i = 1; i <= n; i++)
dis[i] = graph[start][i];
dis[start] = 0;
visited[start] = true;
for (int i = 0; i < n - 1; i++) {
int cur = findSmallestNode();
visited[cur] = true;
for (int j = 1; j <= n; j++) {
if (!visited[j] && graph[cur][j] != Integer.MAX_VALUE) {
if (dis[j] > dis[cur] + graph[cur][j])
dis[j] = dis[cur] + graph[cur][j];
}
}
}
}
static int findSmallestNode() {
int min = Integer.MAX_VALUE;
int v = 0;
for (int i = 1; i <= n; i++) {
if (!visited[i]) {
if (min > dis[i]) {
min = dis[i];
v = i;
}
}
}
return v;
}
}
풀이2 : 다익스트라 - 우선순위 큐, 인접 리스트
위의 풀이와 다르게 '방문하지 않은 노드 중 거리값이 가장 작은 노드'를 선택할 때 우선순위 큐를 사용한다.
priority queue를 사용하면 방문하지 않은 노드 중 거리값이 가장 작은 노드를 선택할 때 O(logE) 시간이 걸리므로, 총 E * logE = O(ElogE)의 시간이 걸린다.
- 먼저 우선순위에 저장할 Edge 클래스를 선언한다. 이 때 Comparable<Edge>를 구현하여 cost 오름차순으로 정렬되도록 한다.
- 인접 리스트를 구현할 graph를 생성할 때 ArrayList<ArrayList<Edge> 타입으로 선언한다.
- 1번 정점에서 i번 정점까지의 최단 경로를 저장하는 dis 배열을 Integer.MAX_VALUE로 초기화한다.
- 방문 체크 배열이 필요없다.
- 우선순위 큐가 알아서 최단 거리의 노드를 앞으로 정렬하므로 기존 최단 거리보다 크다면 무시하면 그만이다. 만약 기존 최단거리보다 더 작은 값을 가지는 노드가 있다면 그 노드와 거리를 우선순위 큐에 넣는다.
코드
import java.util.*;
class Solution {
static class Edge implements Comparable<Edge> {
int vertex;
int cost;
public Edge(int v, int c) {
vertex = v;
cost = c;
}
@Override
public int compareTo(Edge o) {
return this.cost - o.cost;
}
}
static int n;
static ArrayList<ArrayList<Edge>> graph;
static int[] dis;
public int solution(int N, int[][] road, int K) {
n = N;
graph = new ArrayList<>();
for (int i = 0; i <= n; i++)
graph.add(new ArrayList<>());
dis = new int[n+1];
Arrays.fill(dis, Integer.MAX_VALUE);
for (int[] arr : road) {
int a = arr[0];
int b = arr[1];
int c = arr[2];
graph.get(a).add(new Edge(b, c));
graph.get(b).add(new Edge(a, c));
}
dijkstra(1);
int answer = 1;
for (int i = 2; i <= N; i++) {
if (dis[i] <= K)
answer++;
}
return answer;
}
static void dijkstra(int start) {
PriorityQueue<Edge> pq = new PriorityQueue<>();
pq.add(new Edge(start, 0));
dis[start] = 0;
while(!pq.isEmpty()) {
Edge cur = pq.poll();
int vertex = cur.vertex;
int cost = cur.cost;
if (cost > dis[vertex]) continue;
for (Edge edge: graph.get(vertex)) {
if (dis[edge.vertex] > cost + edge.cost) {
dis[edge.vertex] = cost + edge.cost;
pq.add(new Edge(edge.vertex, cost + edge.cost));
}
}
}
}
}
실행 시간 비교

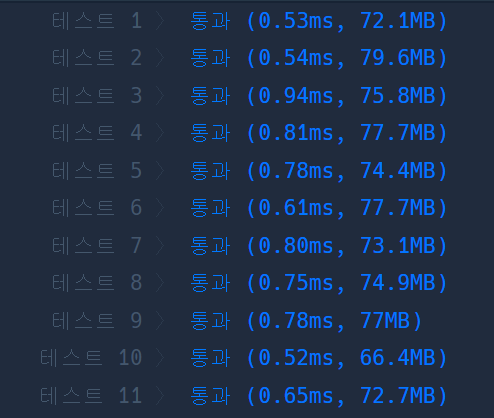
2번째 풀이의 실행시간이 더 크다.
마을(정점)의 개수는 1 이상 50 이하이고, road(간선)의 개수는 1 이상 2,000 이하이므로 O(V^2) 이 O(ElogE)보다 작기 때문에 2번째 풀이의 실행시간이 더 오래 걸린다.
Reference
'Algorithm 문제 풀이 > 프로그래머스' 카테고리의 다른 글
| [프로그래머스] Lv.2 : [1차] 뉴스 클러스터링 - 자바[Java] (0) | 2022.11.15 |
|---|---|
| [프로그래머스] Lv.2 : 튜플 - 자바[Java] (0) | 2022.11.09 |
| [프로그래머스] Lv.2 : 방문 길이 - 자바[Java] (0) | 2022.11.06 |
| [프로그래머스] Lv.2 : 점프와 순간이동 - 자바[Java] (0) | 2022.11.03 |
| [프로그래머스] Lv.2 : 스킬트리 - 자바[Java] (0) | 2022.11.02 |
